据说 数据库文件最大支持 281 T
每个数据库由一个或多个数据页组成,一个数据库内的所有数据页大小都相同,但是不同的数据库可以使用不同的数据页大小,范围从 512 到 65536 字节。
从 sqlite 3.33.0 开始,一个数据库文件最多使用 4294967294 个数据页(由 max_page_count 编译指令决定),意味着最大支持约 2.8e+14 字节(281 TB)
20亿行实践sqlite性能测试记录:
硬盘: 旧机械硬盘
表结构: 共4个字段
CREATE TABLE 测试 ( id INTEGER PRIMARY KEY AUTOINCREMENT, 字段a CHAR UNIQUE, 字段b CHAR, 字段c INT );
第一次 插入了2亿数据 没有计时
第二次 再次插入2亿条数据时 耗时 40多分钟 平均每秒插入8万条左右
第三次 再次插入4亿数据 耗时 4737.079秒 平均每秒也是8.4万条左右,此时文件大小 53.1 GB 表内总行数 8.1亿 行
第四次 再次插入6亿数据 耗时:6400.066秒 平均每秒9.3万条 此时文件大小93.7 GB 表内行数14.1亿行
第五次 再插入6亿数据 耗时:6499.033秒 平均每秒9.3万条 此时文件大小 134 GB 表内行数20.1亿
(可能是第四次因为刚好硬盘要满了 换了块硬盘的原因 插入竟然越来越快了。虽然换了块硬盘,但是也是十年前的老机械硬盘)
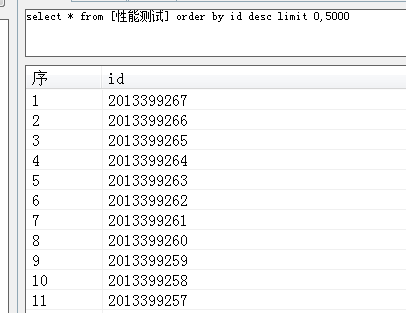
按id查 和 order by id 都正常
执行 select * from 性能测试 where 字段a='xxxx' 耗时70-140毫秒左右, 查询前1亿行的数据 和 8亿行以后的数据 差距不是很大
执行 select * from 性能测试 where 字段b='xxxx' 直接卡死 无法查询
执行 select * from [性能测试] limit 10000000,5000 耗时2000毫秒
执行 select * from [性能测试] limit 20000000,5000 耗时4000毫秒
执行 select * from [性能测试] where id>200000000 limit 0,100 耗时 250毫秒
执行 select * from [性能测试] where id in (1400000000,1300000000,1200000000) 耗时15毫秒
执行 select * from [性能测试] where id>2000000000 and id<2000005000 耗时78毫秒 (说明分批维护是没问题的)
此时 再 执行给字段b增加索引的语句 也是直接卡死 等了半天没反应~~
多线程读取测试 内部sql语句:select * from 性能测试 where 字段a='xxxx'
读取测试,单线程查询
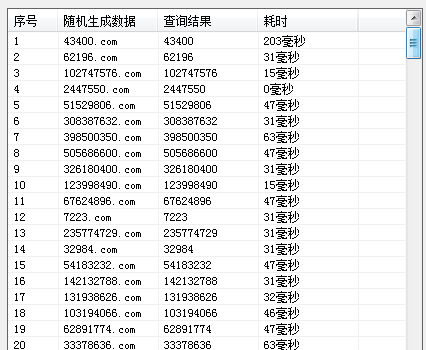
10个线程
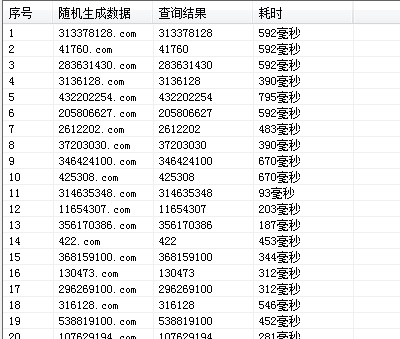
100个线程:
实验证明 虽然多线程 读取数据没有乱 但是速度却慢下来了 说明即使多线程读取 它内部应该也是一个线程一个线程读取的
相关推荐
mysql sqlite取表内最大id语句 取最新插入id 取表行数取最大ID方法一:select MAX(id) from 表名 方法二:select * from sqlite_sequence where name='表名' 以上两种方法 500
sqlite mysql 复制行数据:插入查询结果 insert select 联合使用语句插入一个字段:insert into 表名称 (字段名) select 字段名 from 表名称 where id=39
mysql中tinynt,smallint ,int,bigint的数据类型取值范围最大能取多少?数据类型占用空间取值范围(有符号)取值范围(无符号)小整数型tinynt1字节-128~1270~255大整数型smallint2字节-32768~327670~65535大整数型MEDIUMINT3
php查看mysql表大小 表行数 表多余 表自增id 数据表最大id查看自增id $sql="select Auto_increment from information_schema.tables where TABLE_SCHEMA='{$数据库
sqlite查询列出某字段有重复数据sqlite3 查询列出 指定字段有重复的行数据select * from 表名称 WHERE (字段名) IN (SELECT 字段名 FROM 表名称 GROUP BY 字段名 HAVING
mysql sqlite 删除旧数据 只保留最新的100条完整语句:delete from _sql执行记录 where id in (select id from _sql执行记录 order by id desc limit 100,100000)del
mysql最大行数限制以下内容仅是猜测:一般习惯每建一个表 第一个字段都是id,且是自增的所以感觉可能会取决于自增id的数据类型一般自增id都用int 默认就是20多亿行 如果加了 unsigned 就是40多亿行 超过
zblog mysql数据库访问速度优化 100万篇文章秒开不卡 php版zblog php数据库访问速度优化后,一百万篇文章秒开不卡.(实际上再加一百万也没问题,懒得测试了)最新编辑:升级后 最新测试 300万毫无压力! 并且已全面支持各种主题!详细请看 https://
sqlite创建索引语句 添加索引 增加索引mysql创建索引alter table 表名 add index 索引名 (列名);sqlite创建索引:CREATE INDEX 索引名 ON 表名 (字段a,字段b);
sqlite索引不区分大小写 COllAte NOCAse一直以为如果查询不加order by 就会默认按照自增id顺序排列呢 偶然发现不加order by id的顺序竟然不是顺序的.经过了解发现原来跟索引的创建方式也有关系,创建索引时,以下选项会影响结果的